
Aboubakr KADI
lundi 22 juillet 2024
Observabilité des données
L’intégration de l’observabilité des données dans votre stack data est une étape cruciale pour les organisations qui souhaitent garantir la qualité, la fiabilité et l’efficacité des données dans leurs pratiques de gestion des données. Alors que les entreprises s’appuient de plus en plus sur une prise de décision Data Driven, l’intégrité et la disponibilité des données deviennent primordiales. L’observabilité des données offre une approche globale de surveillance, de diagnostic et de résolution des problèmes de données, permettant une attitude plus proactive envers le maintien de la santé des systèmes de données. Cet article expose l’importance de l’observabilité des données, ses composants clés et les stratégies pour son intégration efficace dans votre stack data.
Comprendre l’observabilité des données
L’observabilité des données est une extension du concept d’observabilité du système en génie logiciel, qui se concentre sur la manière dont les états internes d’un système peuvent être déduits de ses outputs. Dans le contexte de la gestion des données, cela fait référence à la capacité de comprendre pleinement l’état des données de votre système. Cela inclut la surveillance de la qualité des données, la détection des anomalies, le traçage du data lineage et la compréhension de l’impact des problèmes de données sur les processus métier. En mettant en œuvre l’observabilité des données, les organisations peuvent garantir que leurs données sont exactes, cohérentes et fiables.
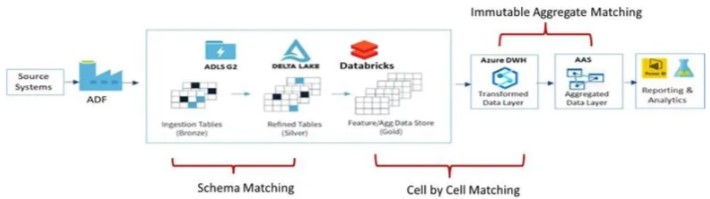
Les composantes clés de l’observabilité de la données
L’observabilité des données comprend plusieurs éléments clés, chacun abordant différents aspects de la santé des données :
Surveillance de la qualité des données
Cela implique une vérification continue des données pour détecter les erreurs, les incohérences et les écarts par rapport aux modèles ou aux normes attendus. Cela aide à identifier les problèmes tels que les valeurs manquantes, les doublons ou les saisies de données incorrectes.
Détection des anomalies
Utilisation de modèles statistiques et de machine learning pour identifier des modèles de données inhabituels susceptibles d’indiquer des problèmes ou des opportunités pour le business.
Data Lineage
Comprendre le flux de données tout au long de leur cycle de vie, de la source à la destination, y compris les transformations qu’elles subissent. Ceci est crucial pour diagnostiquer les problèmes et évaluer l’impact des modifications dans les pipelines de données.
Gestion des métadonnées
Garder une trace des métadonnées (définitions des données) pour fournir un contexte aux ensembles de données, tels que les définitions de schéma, les informations sur les sources de données et l’historique des modifications. Cela facilite la navigation et la gestion des actifs de données.
Ingénierie de la fiabilité des données
Mise en œuvre de pratiques et d’outils pour garantir que les pipelines de données sont robustes, évolutifs et maintenables, minimisant ainsi les temps d’arrêt et la perte de données.
Stratégies pour intégrer l’observabilité des données dans votre pile de données
L’intégration de l’observabilité des données dans votre stack data nécessite une approche stratégique qui englobe la technologie, les processus et les personnes :
Choisissez les bons outils
Sélectionnez des outils offrant des fonctionnalités d’observabilité complètes, notamment des capacités de surveillance, d’alerte et de visualisation. Ces outils doivent bien s’intégrer à votre stack data existante et prendre en charge des workflow automatisés pour détecter et résoudre les problèmes de données.
Mettre en œuvre des politiques de gouvernance des données
Etablir des politiques claires de gouvernance des données qui définissent les normes de qualité des données, la propriété et la responsabilité. Cela garantit que chacun dans l’organisation comprend son rôle dans le maintien de la santé des données.
Favoriser une culture de la qualité des données
Encourager une culture où la qualité des données est la responsabilité de chacun. Fournissez une formation et des ressources pour aider les membres de l’équipe à comprendre l’importance de l’observabilité des données et comment y contribuer.
Automatisez les processus d’observabilité
Tirez parti de l’automatisation pour surveiller en permanence la qualité et les performances des données. Les alertes automatisées peuvent informer les équipes concernées des problèmes, permettant une réponse rapide.
Surveiller et améliorer en continu
L’observabilité des données est un processus continu. Examinez régulièrement les mesures d’observabilité et les commentaires des utilisateurs pour identifier les domaines à améliorer. Affiner continuellement votre approche vous aidera à vous adapter à l’évolution des besoins en matière de données et des technologies.
Code
L’intégration de l’observabilité des données dans votre stack data à l’aide de Python implique plusieurs étapes, de la création d’un ensemble de données synthétiques à la mise en œuvre de métriques d’observabilité et à la génération de graphiques pour visualiser la qualité et les performances des données. Cet exemple vous guidera tout au long du processus, notamment :
- Création d’un ensemble de données synthétiques.
- Définir des métriques d’observabilité.
- Mise en œuvre de contrôles de qualité des données.
- Visualiser les résultats avec des tracés.
Pour les besoins de cet exemple, nous nous concentrerons sur un simple ensemble de données synthétiques liées au E-commerce, comprenant des informations sur les commandes présentant des problèmes potentiels de qualité des données.
Étape 1 : Création d’un ensemble de données synthétiques
Tout d’abord, nous créons un ensemble de données synthétiques représentant les commandes de E-commerce. Notre ensemble de données comprendra l’ID de commande, le nom du produit, la quantité, le prix par article et la date de commande. Nous introduirons quelques anomalies synthétiques telles que des valeurs manquantes et des valeurs aberrantes pour simuler des problèmes de qualité des données.
import pandas as pd
import numpy as np
# Seed for reproducibility
np.random.seed(42)
# Sample dataset
data = {
'order_id': range(1, 101),
'product_name': np.random.choice(['Laptop', 'Tablet', 'Smartphone'], 100),
'quantity': np.random.randint(1, 5, size=100),
'price_per_item': np.random.uniform(100, 1000, size=100).round(2),
'order_date': pd.date_range(start='2023-01-01', periods=100, freq='D')
}
# Introduce missing values and outliers
data['price_per_item'][np.random.choice(100, 10, replace=False)] = np.nan # Missing prices
data['quantity'][np.random.choice(100, 5, replace=False)] = np.random.randint(5, 10, size=5) # Outlier quantities
df = pd.DataFrame(data)
Étape 2 : Définir les métriques d’observabilité
Les mesures d’observabilité de notre ensemble de données incluront la vérification des valeurs manquantes, la détection des valeurs aberrantes et la fraîcheur des données.
def check_missing_values(df):
return df.isnull().sum()
def detect_outliers(df, column):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return df[(df[column] < lower_bound) | (df[column] > upper_bound)]
def data_freshness(df, date_column):
latest_date = df[date_column].max()
current_date = pd.Timestamp('now').normalize()
return (current_date - latest_date).days
Étape 3 : Mise en œuvre des contrôles de qualité des données
Maintenant, nous appliquons les métriques d’observabilité à notre ensemble de données pour identifier tout problème.
# Check for missing values
missing_values = check_missing_values(df)
# Detect outliers in quantity
quantity_outliers = detect_outliers(df, 'quantity')
# Check data freshness
freshness_days = data_freshness(df, 'order_date')
Étape 4 : Visualiser les résultats avec des Plots
Enfin, nous utilisons matplotlib pour visualiser les résultats de nos métriques d’observabilité, telles que la distribution des quantités et des prix, en mettant en évidence les valeurs aberrantes.
import matplotlib.pyplot as plt
# Plotting distribution of quantities with outliers
plt.figure(figsize=(10, 6))
plt.boxplot(df['quantity'].dropna(), vert=False)
plt.title('Quantity Distribution with Outliers')
plt.xlabel('Quantity')
plt.show()
# Plotting missing values in price_per_item
plt.figure(figsize=(10, 6))
plt.hist(df['price_per_item'].dropna(), bins=20, color='skyblue', edgecolor='black')
plt.title('Price Per Item Distribution (Missing Values Excluded)')
plt.xlabel('Price')
plt.ylabel('Frequency')
plt.show()
Ce code Python fournit une approche fondamentale pour intégrer l’observabilité des données dans votre pile de données. Il crée un ensemble de données synthétiques, définit des métriques pour la qualité des données, applique ces métriques pour identifier les problèmes et visualise les résultats. Des ajustements et des extensions peuvent être effectués en fonction d’exigences spécifiques ou d’ensembles de données plus complexes.
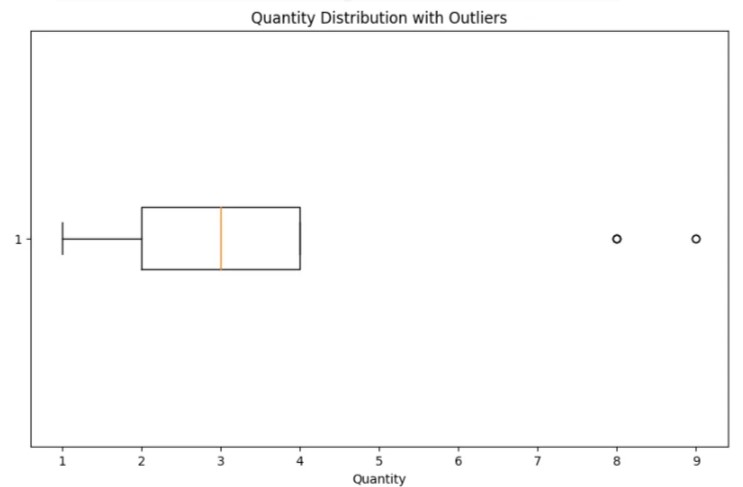
Distribution des quantités avec valeurs aberrantes :
- Le boxplot montre la distribution de la variable « quantité ».
- La box centrale représente les 50 % du milieu des données, encapsulant l’intervalle interquartile (IQR).
- La ligne horizontale à l’intérieur de la box marque la médiane des données.
- Les « moustaches » s’étendent aux valeurs les plus petites et les plus grandes dans une plage de 1,5 fois l’IQR des quartiles inférieur et supérieur, respectivement.
- Les points de données situés en dehors des moustaches sont considérés comme des valeurs aberrantes et sont tracés sous forme de points individuels, comme le montre l’image avec deux points au-delà de la moustache supérieure.
- La présence de valeurs aberrantes suggère qu’il existe des quantités inhabituellement élevées par rapport au reste des données, qui pourraient nécessiter une analyse plus approfondie.
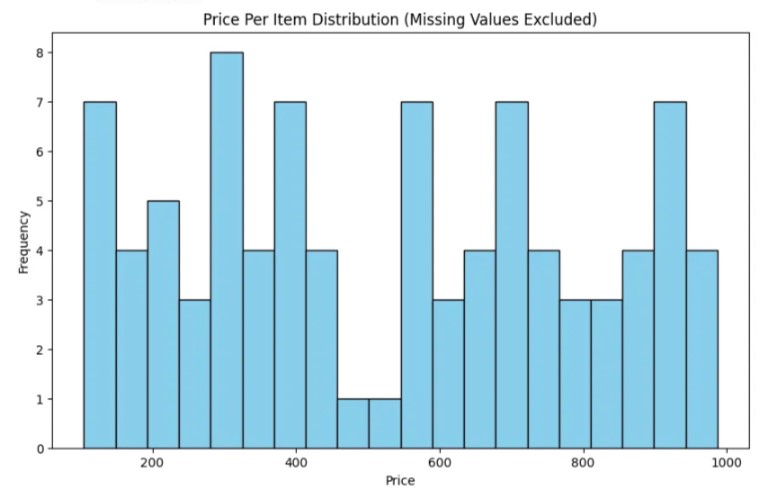
Répartition du prix par article (valeurs manquantes exclues) :
- L’histogramme montre la distribution de la variable « prix par article », en excluant les valeurs manquantes.
- Chaque barre représente la fréquence des prix dans une plage ou une catégorie spécifique.
- La distribution est quelque peu uniforme, aucune catégorie ne dominant la fréquence, ce qui suggère une répartition relativement uniforme des niveaux de prix dans l’ensemble de données.
- Il n’y a pas d’écarts ou de pics visibles dans l’histogramme, ce qui indique l’absence de regroupement significatif ou de valeurs aberrantes de prix. Cependant, sans voir les données elles-mêmes ni connaître le contexte, nous ne pouvons pas savoir avec certitude si l’absence de prix très élevés ou très bas est attendue ou si elle indique des problèmes de qualité des données.
Ces visualisations sont essentielles pour identifier les problèmes potentiels de qualité des données, tels que les valeurs aberrantes ou manquantes, qui sont des aspects importants de l’observabilité des données. Ils fournissent un retour visuel immédiat sur l’état des données, permettant aux ingénieurs de données et aux Analyste de données d’agir et de maintenir la fiabilité de la stack data.
Conclusion
L’intégration de l’observabilité des données dans votre stack data est essentielle pour maintenir une qualité et une fiabilité élevées des données. Il permet aux organisations de détecter et de résoudre les problèmes de données de manière proactive, minimisant ainsi l’impact sur les opérations commerciales. En se concentrant sur les éléments clés de l’observabilité des données et en mettant en œuvre des pratiques d’intégration stratégique, les entreprises peuvent garantir que leurs actifs de données restent une base précieuse et fiable pour la prise de décision. À l’ère des stratégies commerciales basées sur les données, investir dans l’observabilité des données n’est pas seulement bénéfique ; c’est impératif pour un succès durable.